
I’m a Research Scientist at Alibaba Wan Team, where I serve as a core contributor of Wan2.5 and Wan2.6. I also hold a research position at Zhejiang University, working closely with Prof. Yi Yang. I obtained my Ph.D. in Computer Science from Fudan University, supervised by Prof. Yu-Gang Jiang (IEEE Fellow) and Prof. Zuxuan Wu.
I have published 20+ papers ![]()

- 1️⃣ 🌟🌟🌟 Generative models: text-to-video generation, controllable visual generation, video editing
- 2️⃣ Representation learning: video understanding, 3D understanding, image retrieval
If you are interested in discussing potential collaborations, please feel free to email me at zhenxingfd@gmail.com.
🔥 News
- [Feb’2026] 🎈Achieved 1000+ citations on Google Scholar and an h-index of 16.
- [Feb’2026] FlashMotion and FlashPortrait accepted to CVPR 2026.
- [Dec’2025] Wan Team released Wan 2.6. Feel free to try it out!
- [Sep’2025] Wan Team released Wan 2.5.
- [Aug’2025] Released StableAvatar and achieved 1000+ Github stars.
- [Jun’2025] AID and MagicMotion accepted to ICCV 2025.
- [May’2025] Defended Ph.D. thesis and awarded Outstanding Graduates of Shanghai!
- [Apr’2025] Released MagicMotion and achieved 100+ Github stars.
- [Feb’2025] StableAnimator accepted to CVPR 2025 and achieved 1300+ Github stars.
- [Sep’2024] Two papers accepted to NeurIPS 2024.
- [Aug’2024] “A Survey on Video Diffusion Models” accepted to ACM Computing Surveys.
- [Feb’2024] Invited talk at Openmmlab about Video Generation Models, [slides].
- [Feb’2024] SimDA accepted to CVPR 2024.
- [Dec’2023] Invited talk at Kunlun Research, “A Survey on Video Diffusion Models”.
- [Aug’2023] Awarded certificate of “Star of Tomorrow” at MSRA.
- [Feb’2023] Two papers accepted to CVPR 2023.
- [July’2022] Three papers accepted to ECCV 2022.
📝 Publications
A full publication list is available on [Google Scholar] [Semantic Scholar]
(*: equal contribution; †: project leader)

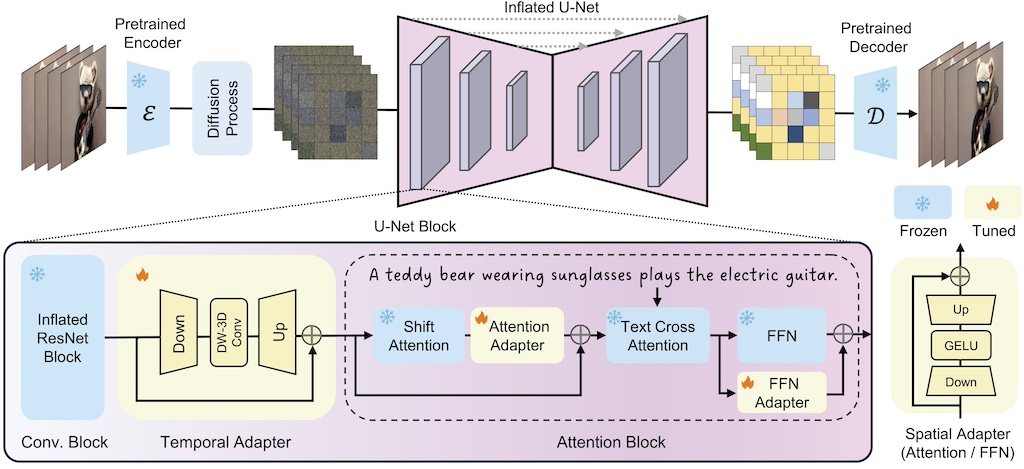
A Survey on Video Diffusion Models
Zhen Xing , Qijun Feng, Haoran Chen, Qi Dai, Han Hu, Hang Xu, Zuxuan Wu, Yu-Gang Jiang
ACM Computing Survey (CSUR, IF=28.0), 2025
[Paper][HomePage][Zhihu][机器之心][量子位]
Surveying 300+ recent literatures on video generation and editing with diffusion models. Acheving Github 2100+ stars.
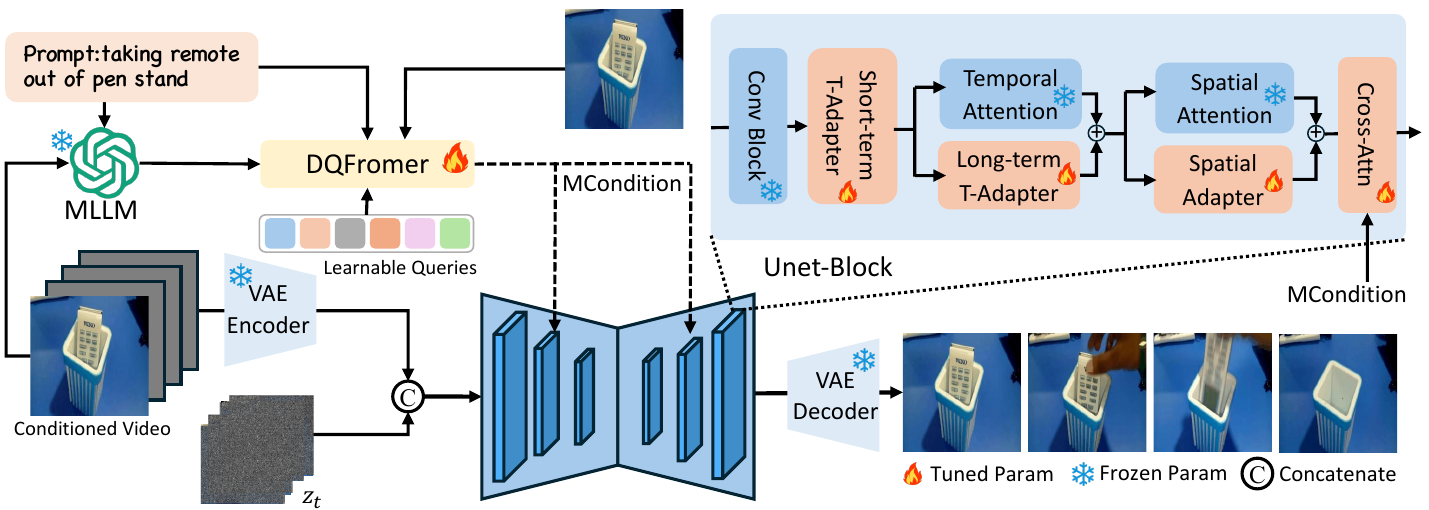
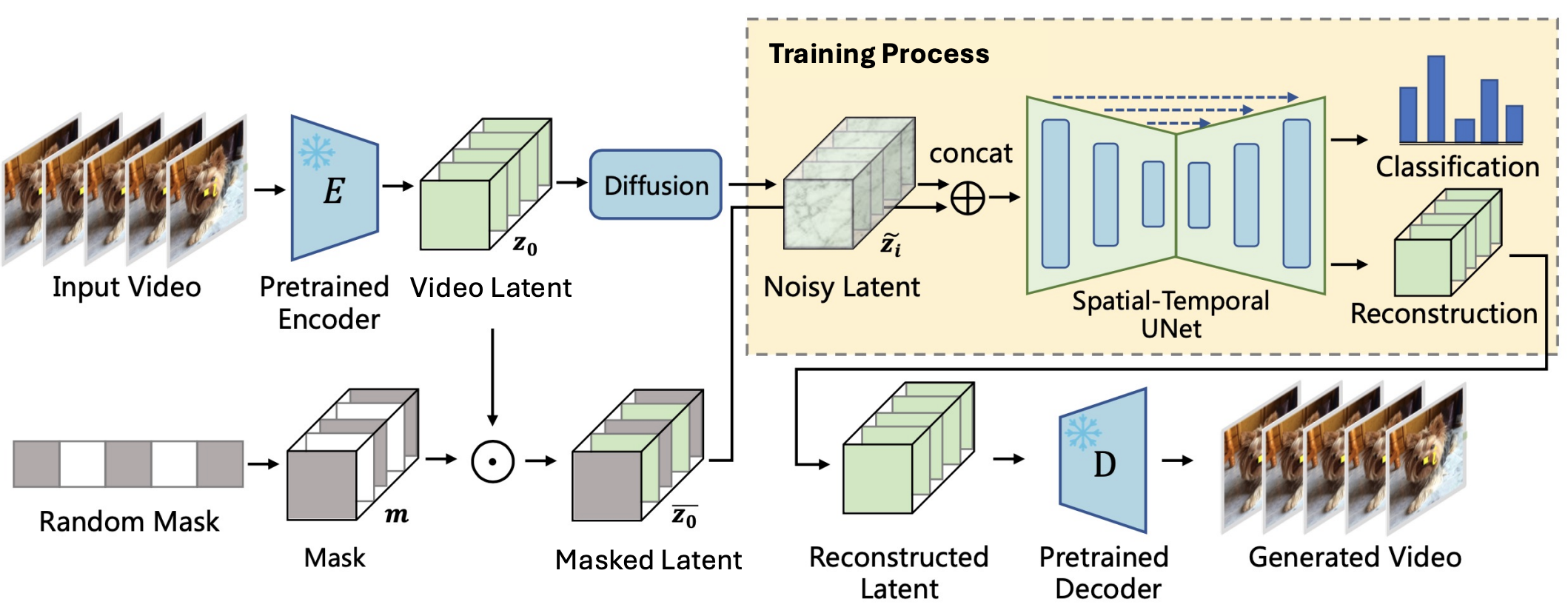
GenRec: Unifying Video Generation and Recognition with Diffusion Models
Zejia Weng, Xitong Yang, Zhen Xing, Zuxuan Wu, Yu-Gang Jiang
Annual Conference on Neural Information Processing Systems (NeurIPS), 2024
[Paper]
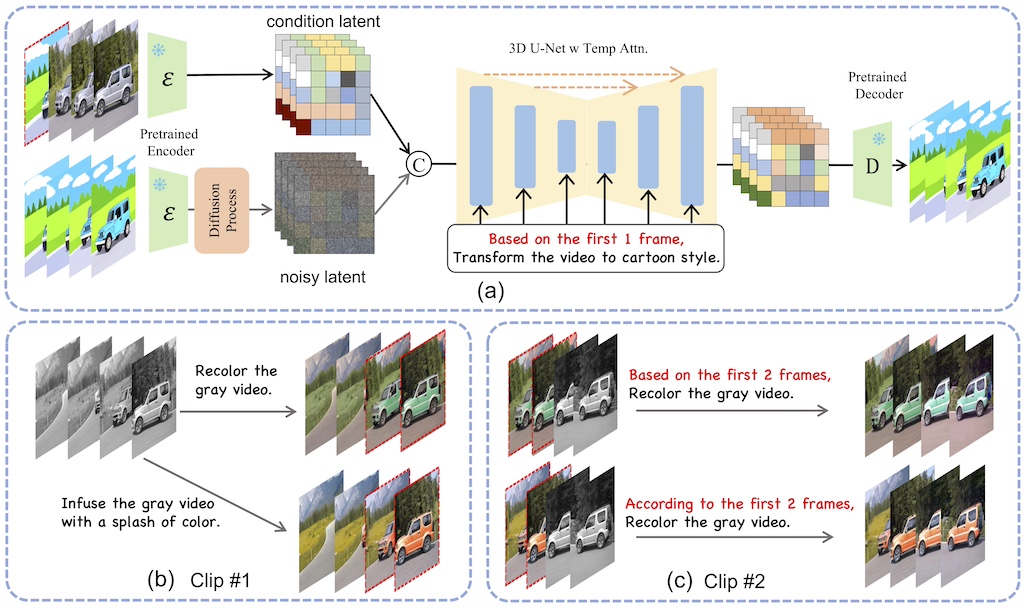
-
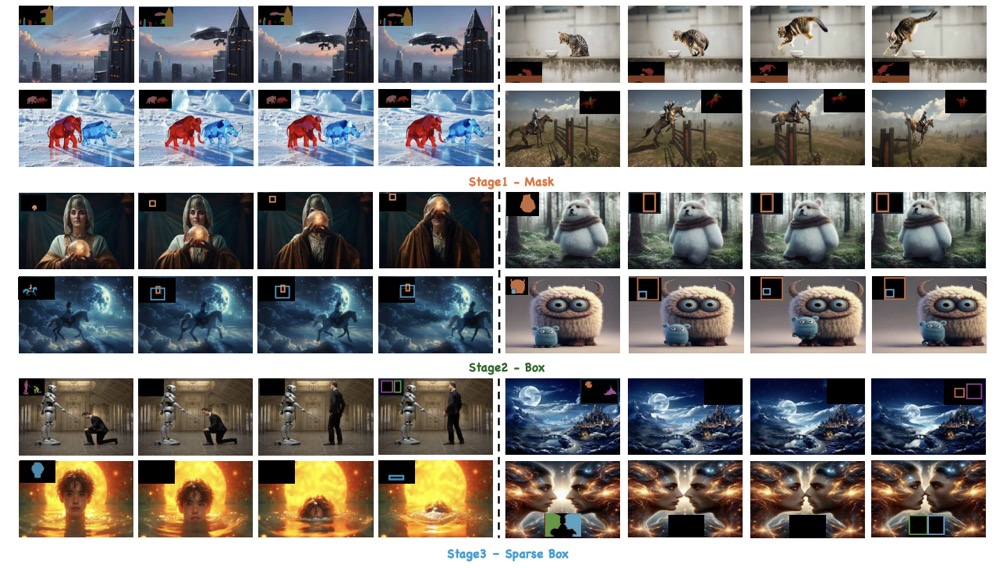
FlashMotion: Few-Step Controllable Video Generation with Trajectory Guidance
Quanhao Li, Zhen Xing, Rui Wang, Haidong Cao, Qi Dai, Daoguo Dong, Zuxuan Wu
, [Paper]
-
FlashPortrait: 6x Faster Infinite Portrait Animation with Adaptive Latent Prediction
Shuyuan Tu, Yueming Pan, Yinming Huang, Xintong Han, Zhen Xing, Qi Dai, Kai Qiu, Chong Luo, Zuxuan Wu
-
Human2Robot: Learning Robot Actions from Paired Human-Robot Videos
Sicheng Xie, Haidong Cao, Zejia Weng, Zhen Xing, Shiwei Shen, Jiaqi Leng, Xipeng Qiu, Yanwei Fu, Zuxuan Wu, Yu-Gang Jiang
, [Paper]
-
StableAnimator++: Overcoming Pose Misalignment and Face Distortion for Human Image Animation
Shuyuan Tu, Zhen Xing, Xintong Han, Zhi-Qi Cheng, Qi Dai, Chong Luo, Zuxuan Wu, Yu-Gang Jiang
, [Paper]
-
ProLongVid: A Simple but Strong Baseline for Long-context Video Instruction Tuning
Rui Wang, Bohao Li, Xiyang Dai, Jianwei Yang, Yi-Ling Chen, Zhen Xing, Yifan Yang, Dongdong Chen, Xipeng Qiu, Zuxuan Wu, Yu-Gang Jiang
, [Paper]
-
AdaDiff: Adaptive Step Selection for Fast Diffusion
Hui Zhang, Zuxuan Wu, Zhen Xing, Jie Shao, Yu-Gang Jiang
, [Paper]
-
Advancing Dark Action Recognition via Modality Fusion and Dark-to-Light Diffusion Model
Yuxuan Wang, Zhen Xing, Zuxuan Wu
, [Paper]
-
Aligning Vision Models with Human Aesthetics in Retrieval: Benchmarks and Algorithms
Miaosen Zhang, Yixuan Wei, Zhen Xing, Yifei Ma, Zuxuan Wu, Ji Li, Zheng Zhang, Qi Dai, Chong Luo, Xin Geng, Baining Guo
, [Paper]
-
FDGaussian: Fast Gaussian Splatting via Geometric-aware Diffusion Model
Qijun Feng, Zhen Xing, Zuxuan Wu, Yu-Gang Jiang
, [Paper], [HomePage]
-
TranSFormer: Slow-Fast Transformer for Machine Translation
Bei Li, Yi Jing, Xu Tan, Zhen Xing, Tong Xiao, Jingbo Zhu
, [Paper]
-
Multi-Level Region Matching for Fine-Grained Sketch-Based Image Retrieval
Zhixin Ling, Zhen Xing, Jiangtong Li, Li Niu
, [Paper]
-
3D-Augmented Contrastive Knowledge Distillation for Image-based Object Pose Estimation
Zhidan Liu, Zhen Xing, Xiangdong Zhou, Yijiang Chen, Guichun Zhou
[Paper]
-
CaSS: A Channel-aware Self-supervised Representation Learning Framework for Multivariate Time Series Classification
Yijiang Chen, Xiangdong Zhou, Zhen Xing, Zhidan Liu, Minyang Xu
, [Paper]
-
From Coarse to Fine: Hierarchical Structure-aware Video Summarization
Wenxu Li, Gang Pan, Chen Wang, Zhen Xing, Zhenjun Han
, [Paper]
🎖 Honors and Awards
Below, I exhasutively list some of my Honors and Awards that inspire me a lot.
- Outstanding graduates of Shanghai. (Top-1%, PhD) [2025]
- Alibaba Star Program and Tencent Qingyun Plan. [2025]
- Tencent academic scholarship. (Top-3%, PhD) [2024]
- Fudan University excellent academic scholarship. (Top-5%, PhD) [2023]
- “Star of Tomorrow” intern of MicroSoft Research Asia. (Top 10%, PhD)[2023]
- Tencent academic scholarship. (Rank 1/130, PhD) [2022]
- Fudan University excellent academic scholarship. (Top-5%, Master) [2021]
- Outstanding graduates of TianJin University. (Top-5%) [2020]
- Excellent monitor of Tianjin University. (Top-10) [2018]
- Academic scholarship of Tianjin University. (Top-10%) [2017-2020]
💬 Invited Talks
- 2024.04, Talk at ByteDance, SimDA: Simple Diffusion Adapter for Efficient Video Generation [slides]
- 2024.02, Tutorial at Openmmlab, The Past and Present of Video Diffusion Models [slides]
- 2023.12, Tutorial at Kunlun Research, The Tutorial of Video Generative Models [slides]
💻 Internships
- 2022.03 - 2023.08, MicroSoft Research Asia, Visual Computing Group.
🎓 Academic Service
- Conference Program Committee:
- IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2022-2025
- IEEE/CVF International Conference on Computer Vision (ICCV) 2023-2025
- European Conference on Computer Vision (ECCV) 2022-2024
- International Conference on Learning Representations (ICLR) 2024-2025
- ACM SIGGRAPH Conference (SIGGRAPH) 2025
- International Conference on Machine Learning (ICML) 2024-2025
- Conference on Neural Information Processing Systems (NeurIPS) 2024-2025
- AAAI Conference on Artificial Intelligence (AAAI) 2023-2025
- Journal Reviewer:
- IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI)
- International Journal of Computer Vision (IJCV)
- IEEE Transactions on Multimedia (TMM)
- IEEE Transactions on Circuits and Systems for Video Technology (TCSVT)
- Knowledge-Based Systems (KBS)
- Pattern Recognition (PR)